# IPCQ-DMA Co-design Hardware Design Document
**Status**: Draft — Review Requested
**Date**: 2026-04-28
**Authors**: YW Kang
**Reviewers**: (HW team TBD)
**Related**: ADR-0023 (IPCQ PE Collective), ADR-0025 (Direction Addressing)
---
## 1. Background & Motivation
IPCQ(Inter-PE Communication Queue)는 PE 간 collective communication을 위한
하드웨어 큐 메커니즘이다. 핵심 설계 원리는 **DMA가 데이터 전송 시 별도의
제어 메시지 없이, piggyback된 메타 정보를 바탕으로 IPCQ의 head/tail pointer를
자동 업데이트**하는 IPCQ-DMA co-design이다.
이 문서는:
1. 현재 PE 아키텍처에서 IPCQ가 하드웨어 수준에서 어떻게 동작하는지 기술하고,
2. 이 하드웨어를 시뮬레이터에서 어떻게 모델링하고 있는지 검증하며,
3. 실제 하드웨어 구현을 위한 설계를 제안하고,
4. 대안들을 검토하여 최적 접근을 확정한다.
---
## 2. High-level Behavior of PE_IPCQ
> source: [`diagrams/pe_baseline.d2`](diagrams/pe_baseline.d2) — `d2 --layout=elk --scale 1.5` 로 렌더링.
### IPCQ 하드웨어 동작
**HW Configuration**:
* IPCQ는 PE 간에 ring buffer 기반의 단방향 큐를 설정하여 데이터를 전달한다.
* 각 PE는 방향별(N/S/E/W 등)로 독립적인 queue pair 를 유지한다.
* IPCQ는 각 queue pair 마다 sender's head/tail pointer, receiver's head/tail pointer 를 유지한다.
* **IPCQ Slot Region**: IPCQ의 수신 버퍼로, 다이어그램의 점선 박스로 표시된 것처럼 TCM, Cube SRAM, Local HBM 중 하나를 buffer_kind로 지정하여 사용할 수 있다.
각 tier별 성능 특성 (시뮬레이션 모델 값, `ipcq_types.py`):
| Buffer Kind | Intrinsic BW | Effective BW (NoC bottleneck) | 용도 |
|-------------|-------------|-------------------------------|------|
| TCM | 512 GB/s | 512 GB/s (직결, NoC 미경유) | 최저 latency, PE 내부 전용 |
| Cube SRAM | 512 GB/s | 128 GB/s (`sram_to_router_bw`) | Cube 내 공유, NoC BW에 제한 |
| Local HBM | 256 GB/s | 256 GB/s (`hbm_to_router_bw`) | 대용량, NoC BW에 제한 |
**Send 경로 (fire-and-forget)**:
1. PE_CPU가 `tl.send(dir, src_addr)` 발행 → PE_IPCQ에 IpcqRequest 전달
2. PE_IPCQ가 backpressure 확인: `(my_head - peer_tail_cache) < peer.n_slots`
3. Peer의 rx slot 주소 계산: `peer_rx_base + (my_head % n_slots) × slot_size`
4. IpcqDmaToken(data + piggyback metadata: sender_seq)을 PE_DMA에 전달
5. PE_IPCQ가 `my_head++`, PE_CPU에 즉시 반환 (DMA 완료를 기다리지 않음)
6. PE_DMA가 src data를 snapshot 후 NoC를 통해 peer PE_DMA로 전송
**Receive 경로 (blocking)**:
1. Peer PE_DMA가 data를 slot에 write하고, **같은 사이클에** metadata(sender_seq, dst_addr)를 추출
2. PE_IPCQ가 dst_addr range matching으로 방향을 식별, `peer_head_cache` 업데이트
3. `tl.recv(dir)` 대기 중인 PE_CPU에 wakeup signal 전달
4. PE_CPU가 slot에서 데이터 읽기, PE_IPCQ가 `my_tail++`
5. **Credit return**: PE_IPCQ가 16B credit packet(`consumer_seq`)을 NoC를 통해 sender에게 전송
6. Sender PE_IPCQ가 `peer_tail_cache` 업데이트, backpressure 해제
**핵심 설계 원리**:
- **Data + head pointer piggyback**: 별도의 head 동기화 메시지 없이, DMA data flit에 sender_seq를 실어보냄
- **Atomic write + metadata**: 수신측 DMA가 slot write와 metadata 전달을 같은 사이클에 수행 (I6 invariant)
- **Address-based direction matching**: 같은 peer에 여러 방향이 연결되어도 dst_addr range로 구분 (ADR-0025)
- **Credit-based flow control**: Receiver가 slot 소비 후 16B credit으로 sender에게 알림
---
## 3. Simulator Implementation Verification
위의 하드웨어 동작을 시뮬레이터에서 어떻게 모델링하는지 검증한다.
### 3.1 의도와 구현의 매핑
| 설계 의도 | 시뮬레이터 구현 | 위치 |
|-----------|----------------|------|
| DMA가 데이터 전송 시 head pointer를 piggyback | `IpcqDmaToken.sender_seq` 필드가 data flit과 함께 전달 | `ipcq_types.py:185` |
| 수신측 DMA가 data write + metadata 전달을 atomic 처리 | `_handle_ipcq_inbound`에서 `store.write` → `IpcqMetaArrival` 사이에 yield 없음 (I6) | `pe_dma.py:232-275` |
| Send는 fire-and-forget | `_handle_ipcq_outbound`에서 `sub_done`을 기다리지 않음 | `pe_dma.py:182` |
| Recv는 데이터 도착까지 block | `peer_head_cache > my_tail` 조건으로 대기 | `pe_ipcq.py:263` |
| Credit return은 별도 fast-path | SimPy Store를 통한 direct put (latency는 NoC 경로 기반으로 charge) | `pe_ipcq.py:443-469` |
| In-flight data semantics (snapshot) | Send 시점에 data snapshot 보존, 이후 src 수정과 무관 | `pe_dma.py:142-155` |
| PE_DMA 단일 inbox | 모든 in_port를 `_fan_in`으로 단일 FIFO에 merge (`base.py:51-53`) | compute port와 IPCQ port 사이에 arbiter 없음 |
### 3.2 Credit Return Path 모델링 상세
Credit return은 실제 NoC 경로를 `router.find_path()`로 찾고,
`compute_path_latency_ns()`로 hop latency + BW drain을 계산하여 charge한다.
```python
# pe_ipcq.py:471-492
def _credit_latency_ns(self, direction: str) -> float:
path = self.ctx.router.find_path(self._pe_prefix, peer_pe_dma)
return self.ctx.compute_path_latency_ns(path, self._credit_size_bytes)
```
단, latency를 `env.timeout()`으로 지불한 후 `peer_credit_store`(SimPy Store)에
직접 put하는 방식이다. 실제 `Transaction`을 만들어 NoC를 hop-by-hop 통과시키지는
않으므로, **다른 트래픽과의 bandwidth contention은 모델링되지 않는다.**
| | Latency | BW Contention |
|---|---|---|
| Data path (IpcqDmaToken) | NoC Transaction으로 정확 모델링 | 실제 fabric 통과 |
| Credit path (16B) | NoC 경로 latency 정확 반영 | fabric Transaction 미주입 (단순화) |
Credit은 16B로 data transfer(수십~수백 KB) 대비 무시 가능한 크기이므로,
이 단순화로 인한 실질적 오차는 거의 없다.
### 3.3 검증 결론
시뮬레이터 구현은 IPCQ-DMA co-design 의도를 **정확하게 모델링**하고 있다.
---
## 4. Proposed Hardware Design
### 4.1 Block Diagram (변경 후)
변경점을 강조 표시: **(NEW)** = 신규, **(MOD)** = 수정.
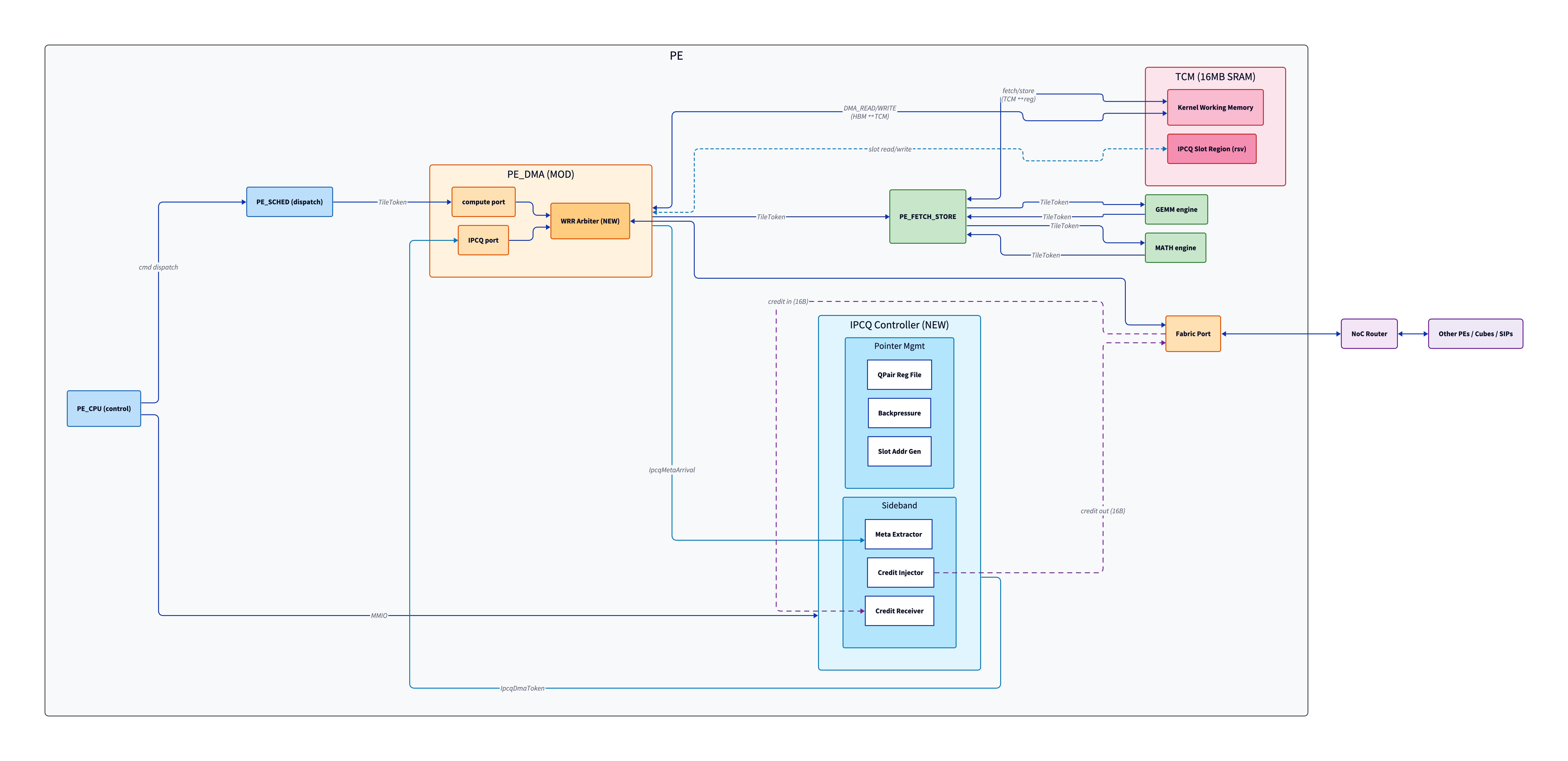
> Source: [`diagrams/pe_proposed.d2`](diagrams/pe_proposed.d2) — `d2 --layout=elk` 로 렌더링.
**Baseline → Proposed 핵심 변경**:
- 단일 FIFO inbox → **compute port / IPCQ port 분리 + WRR Arbiter** (NEW)
- PE_IPCQ (SimPy component) → **IPCQ Controller** (HW register + combinational logic)
- TCM 내 **IPCQ Slot Region 예약 영역** 명시
- Credit Injector / Receiver가 Fabric Port를 통해 NoC에 직접 연결
### 4.2 Module Details
#### 4.2.1 IPCQ Controller (신규 모듈)
PE_CPU와 DMA Engine 사이에 위치하는 하드웨어 제어 블록.
시뮬레이터의 `PeIpcqComponent`에 대응한다.
##### QPair Register File
방향별 queue pair 상태를 flip-flop으로 유지한다.
```
Per-direction registers (each 64-bit):
my_head — sender write position (monotonic)
my_tail — receiver read position (monotonic)
peer_head_cache — last known peer head (updated by Meta Extractor)
peer_tail_cache — last known peer tail (updated by Credit Receive)
rx_base_pa — this PE's rx buffer base physical address
peer_rx_base_pa — peer's rx buffer base physical address
n_slots — ring depth (power-of-2 제약, 아래 참조)
slot_size — bytes per slot
peer_credit_tgt — peer PE의 credit receive 주소
Directions: 최대 8 (N/S/E/W/parent/child_left/child_right + spare)
Total: 8 dirs × 9 regs × 8B = 576B flip-flops
```
PE_CPU가 MMIO(CSR)로 읽기/쓰기 가능. Init 시점에 소프트웨어가 채워넣는다.
##### Slot Address Generator (combinational)
```
Input: pointer (my_head or my_tail), n_slots, slot_size, base_pa
Output: slot_addr = base_pa + (pointer % n_slots) * slot_size
Implementation:
n_slots power-of-2 제약 → pointer & (n_slots - 1) (AND mask, 1 gate delay)
slot_size power-of-2 → barrel shift (1 cycle)
64-bit add → ripple/kogge-stone adder (1 cycle)
Latency: 1-2 cycles combinational
```
##### Backpressure Comparator (combinational)
```
full = (my_head - peer_tail_cache) >= n_slots
Implementation: 64-bit subtract + unsigned compare
Output: stall signal → PE_CPU (IPCQ send blocked) or DMA issue hold
Latency: 1 cycle
```
##### Meta Extractor (inbound datapath sideband)
DMA Engine의 inbound vc_comm path에 wired. Arriving IPCQ flit의 header에서
metadata를 추출하여 queue pair 상태를 업데이트한다.
```
Trigger: DMA inbound write completion (same cycle)
Extract: {sender_seq, dst_addr} from flit header
Direction matching (ADR-0025 D2):
for each dir:
match = (base_pa[dir] <= dst_addr) && (dst_addr < base_pa[dir] + n_slots[dir] * slot_size[dir])
8× parallel range comparators + priority encoder
Update: peer_head_cache[matched_dir] = max(peer_head_cache, sender_seq + 1)
Output: recv_wake signal for matched direction → PE_CPU interrupt/flag
Implementation: 8× (2 comparators + AND) + priority encoder
Latency: 1 cycle (pipelined with DMA write — I6 atomicity 자연 보장)
```
##### Credit Injector (outbound)
```
Trigger: recv completion (my_tail 증가 후)
Action: pack 16B credit packet → DMA vc_comm (또는 dedicated credit VC)
Packet: {consumer_seq = my_tail, dst_rx_base_pa = my_rx_base_pa}
Latency: 1 cycle to generate, then NoC traversal
```
##### Credit Receiver (inbound sideband)
```
Trigger: 16B credit packet arrival (from NoC)
Extract: {consumer_seq, dst_rx_base_pa}
Direction matching (ADR-0025 D3):
for each dir:
match = (peer_rx_base_pa[dir] == credit.dst_rx_base_pa)
Update: peer_tail_cache[matched_dir] = max(peer_tail_cache, consumer_seq)
Output: send_wake signal → deassert backpressure stall
Latency: 1 cycle
```
#### 4.2.2 DMA Engine 수정사항
##### vc_comm IPCQ-aware mode
기존 vc_comm 채널에 IPCQ flit 처리 모드를 추가한다.
**Outbound**:
1. IPCQ Controller로부터 command 수신: {src_addr, dst_addr, nbytes, sender_seq}
2. TCM에서 src_addr read → DMA read buffer에 snapshot (기존 DMA behavior)
3. Flit pack: data + piggyback metadata (sender_seq, dst_addr)
4. NoC fabric port에 inject
5. Fire-and-forget (completion을 기다리지 않음)
**Inbound**:
1. NoC로부터 IPCQ flit 수신
2. Terminal BW drain charge (drain_ns = nbytes / bottleneck_bw)
3. Slot write latency charge (backing memory tier)
4. **ATOMIC** (same pipeline stage, no stall insertion):
- TCM write: data → slot address
- Meta Extractor trigger: sender_seq + dst_addr → IPCQ Controller
5. Done
**I6 atomicity 하드웨어 보장**: TCM write completion과 Meta Extractor trigger가
동일 pipeline stage에서 발생하므로 별도 synchronization이 불필요하다.
시뮬레이터의 "no yield between write and IpcqMetaArrival"이 자연스럽게 보장된다.
##### Data Snapshot Semantics
DMA read buffer에 latch된 데이터는 src memory의 이후 수정에 영향받지 않는다.
이는 DMA의 standard read-then-write behavior이므로 추가 HW가 불필요하다.
##### Credit Virtual Channel (선택적)
옵션 A: vc_comm에 credit을 multiplexing (16B header-only flit으로 구분)
옵션 B: 3rd dedicated credit VC 추가 (strict priority > data)
옵션 B가 deadlock prevention에 유리하나, 16B credit의 BW 영향이 무시 가능하므로
옵션 A로도 충분하다.
#### 4.2.3 Fabric Flit Format 확장
```
일반 data flit (예: 512-bit):
┌──────────────────────────────────────────┐
│ [511:480] routing header (32b) │
│ [479:0] payload (480b = 60B) │
└──────────────────────────────────────────┘
IPCQ data flit (첫 flit에만 metadata 포함):
┌──────────────────────────────────────────┐
│ [511:480] routing header (32b) │
│ [511] ipcq_flag (1b) │ ← IPCQ vs normal DMA 식별
│ [510:509] vc_id (2b) │
│ [508:480] route + hop count │
│ [479:416] ipcq_metadata (64b) │ ← piggyback
│ [479:448] sender_seq (32b) │
│ [447:416] dst_addr[31:0] (32b) │ ← direction matching용
│ [415:0] payload (416b = 52B) │
└──────────────────────────────────────────┘
후속 flits: full 60B payload (metadata 없음)
Credit-only flit (128-bit, header-only):
┌──────────────────────────────────────────┐
│ [127:96] routing header (32b) │
│ [127] credit_flag (1b) │
│ [95:64] consumer_seq (32b) │
│ [63:0] dst_rx_base_pa (64b) │
└──────────────────────────────────────────┘
```
첫 flit의 payload가 60B → 52B로 감소 (13% overhead).
Multi-flit transfer에서는 후속 flit이 full payload이므로 대형 전송에서 overhead < 1%.
#### 4.2.4 TCM IPCQ Slot Region
```
TCM Memory Map (16MB):
┌─────────────────────────────┐ 0x000000
│ Kernel Working Memory │
│ (compute tensors) │
│ ~14MB │
├─────────────────────────────┤ 0xE00000
│ IPCQ RX Buffers │
│ Dir N: slots × slot_size │
│ Dir S: slots × slot_size │
│ Dir E: slots × slot_size │
│ Dir W: slots × slot_size │
│ ~1MB │
├─────────────────────────────┤ 0xF00000
│ IPCQ Metadata / Scratch │
│ ~1MB │
└─────────────────────────────┘ 0xFFFFFF
```
IPCQ region을 TCM의 상위 bank에 배치하여 compute access와의
bank conflict를 최소화한다 (Section 6.1 참조).
---
## 5. End-to-End Dataflow
### 5.1 Sequence Diagram
```mermaid
sequenceDiagram
participant CPU_A as PE_A: PE_CPU
participant IPCQ_A as PE_A: IPCQ Ctrl
participant DMA_A as PE_A: DMA
participant NOC as NoC Fabric
participant DMA_B as PE_B: DMA
participant IPCQ_B as PE_B: IPCQ Ctrl
participant TCM_B as PE_B: TCM
participant CPU_B as PE_B: PE_CPU
Note over CPU_A: tl.send(dir="E", src=0x1000)
CPU_A->>IPCQ_A: MMIO: send request
Note over IPCQ_A: Backpressure check:
(head - peer_tail_cache) < n_slots → PASS
Slot addr gen:
dst = peer_rx_base + (head%n) × slot_size
IPCQ_A->>DMA_A: IpcqDmaToken {src, dst, sender_seq=head}
Note over IPCQ_A: my_head++
IPCQ_A-->>CPU_A: send returns (fire-and-forget)
Note over DMA_A: TCM read → snapshot in read buffer
Flit pack: data + {sender_seq, dst_addr}
DMA_A->>NOC: IPCQ data flit(s)
Note over NOC: hop latency + BW drain
NOC->>DMA_B: IPCQ data flit(s)
Note over DMA_B: Terminal BW drain
Slot write latency
rect rgb(255, 240, 220)
Note over DMA_B,IPCQ_B: ATOMIC (I6): same cycle, no stall
DMA_B->>TCM_B: write data → slot address
DMA_B->>IPCQ_B: Meta Extractor: {sender_seq, dst_addr}
end
Note over IPCQ_B: Range match dst_addr → direction "W"
peer_head_cache["W"] = sender_seq + 1
IPCQ_B-->>CPU_B: recv_wake signal
Note over CPU_B: tl.recv(dir="W") wakes up
CPU_B->>IPCQ_B: recv request
Note over IPCQ_B: peer_head_cache > my_tail → YES
slot_addr = rx_base + (tail%n) × slot_size
IPCQ_B-->>CPU_B: return slot_addr
CPU_B->>TCM_B: read data from slot
Note over IPCQ_B: my_tail++
IPCQ_B->>NOC: Credit (16B): {consumer_seq, dst_rx_base_pa}
Note over NOC: credit traversal (NoC latency)
NOC->>IPCQ_A: Credit arrival
Note over IPCQ_A: Match dst_rx_base_pa → direction "E"
peer_tail_cache["E"] = consumer_seq
Backpressure deassert (if stalled)
```
---
## 6. 2nm Implementation Analysis
### 6.1 Area Estimate
| Module | Gate Count | Area (2nm est.) | Notes |
|--------|-----------|-----------------|-------|
| QPair Register File | ~4.6K FF | 0.002 mm² | 576B flip-flops |
| Slot Addr Gen + Backpressure | ~5K gates | 0.001 mm² | Combinational |
| Meta Extractor + Credit Logic | ~3K gates | 0.001 mm² | 8× parallel comparators |
| **Total IPCQ Controller** | **~12.6K** | **~0.004 mm²** | **PE 전체 대비 < 0.1%** |
| DMA vc_comm 확장 | ~2K gates | 0.002 mm² | Flit pack/unpack |
| **Total 변경분** | **~14.6K** | **~0.006 mm²** | |
### 6.2 Timing
| Path | Delay (2nm est.) | Target Clock | Margin |
|------|-------------------|-------------|--------|
| Backpressure (sub + cmp) | ~0.3 ns | 1 GHz (1 ns) | 3× |
| Slot Addr Gen (mask + shift + add) | ~0.5 ns | 1 GHz | 2× |
| Meta Extractor (8× range match) | ~0.4 ns | 1 GHz | 2.5× |
| Credit Receiver (8× equality) | ~0.3 ns | 1 GHz | 3× |
모든 critical path가 1 cycle 이내. Timing closure 문제 없음.
### 6.3 Power
- Active: ~1 mW (register read/write + comparators, send/recv 동작 시)
- Idle: leakage only
- PE 전체 전력 대비 무시 가능
### 6.4 Constraints
| 항목 | 제약 | 근거 |
|------|------|------|
| `n_slots` | **반드시 power-of-2** | mod → AND mask (1 gate). 임의 값은 divider 필요 (~10 cycles) |
| `slot_size` | **power-of-2 권장** | mul → barrel shift. 임의 값은 multiplier 필요 |
| TCM IPCQ region | **전용 bank 배치** | Compute access와 bank conflict 방지 |
---
## 7. Risk Assessment
### 7.1 TCM Bank Conflict
- **Risk**: IPCQ slot write와 compute read가 동일 bank 접근 시 stall
- **Mitigation**: IPCQ region을 TCM 상위 address의 전용 bank에 배치
- **Cost**: TCM banking flexibility 소폭 감소
- **Severity**: Medium (성능 영향), Low (correctness 문제 아님)
### 7.2 Credit Return Latency under Congestion
- **Risk**: NoC 혼잡 시 credit return 지연 → sender backpressure stall
- **Mitigation**:
- Credit을 별도 VC로 분리 + strict priority (16B로 BW impact 미미)
- 또는 n_slots를 넉넉히(8+) 설정하여 credit 지연을 buffer로 흡수
- **Severity**: Low (credit 16B는 congestion에 거의 기여하지 않음)
### 7.3 Inter-Direction Ordering
- **Risk**: 같은 PE에서 여러 방향으로 동시 send 시 순서
- **Mitigation**: Per-direction monotonic seq으로 충분. Inter-direction ordering은
kernel(소프트웨어) 책임 — 현재 시뮬레이터 모델과 동일
- **Severity**: Low (아키텍처 설계에 의해 해소)
---
## 8. Alternatives Considered
### 8.1 Doorbell + Polling (전통적 방식)
```
Send: DMA write data → DMA write doorbell register at peer → peer polls doorbell
Recv: Polling loop on doorbell, or interrupt-driven
```
| 장점 | 단점 |
|------|------|
| 단순한 HW (IPCQ controller 불필요) | 2번의 DMA transaction (data + doorbell) |
| 기존 DMA 재사용 | Data/doorbell 사이 ordering 보장 필요 (fence) |
| | Polling은 전력 낭비, interrupt는 latency overhead |
**평가**: Piggyback 대비 latency 2-3× 증가. **불채택.**
### 8.2 Hardware Message Queue (NVIDIA NVLink 스타일)
```
Send: CPU → HMQ에 descriptor push → HW가 peer HMQ로 자동 전달
Recv: HMQ에서 descriptor pop → data pointer 확인
```
| 장점 | 단점 |
|------|------|
| CPU는 descriptor만 작성 | 별도 HMQ engine 필요 (~0.05 mm²) |
| Descriptor/data 분리 → 유연 | DMA와 별개 datapath → area/power 중복 |
| | Large tensor에는 결국 DMA 필요 |
**평가**: CCL의 large tensor 패턴에서 DMA 필수이므로 HMQ + DMA 이중 구조는
면적 낭비. **불채택.**
### 8.3 RDMA-style Completion Queue (CQ)
```
Send: DMA write → peer에 CQE 자동 생성
Recv: CQ poll/interrupt → data 위치 확인
```
| 장점 | 단점 |
|------|------|
| InfiniBand/RoCE 성숙 모델 | CQ 관리 logic + CQE memory overhead |
| Multi-tenant/isolation 용이 | CQE/data ordering 보장 추가 필요 |
| | PE-to-PE CCL에는 over-engineered |
**평가**: RDMA CQ는 host-facing NIC의 multi-tenant 격리에 적합.
PE 간 단일 owner 환경에서는 불필요한 복잡성. **불채택.**
### 8.4 Credit-in-Data Piggyback (v2 최적화 후보)
현재 설계에서 credit return은 별도 16B packet이다.
Bidirectional 통신 패턴에서는 **reverse 방향 data flit에 credit을 합칠 수 있다.**
```
PE_A →E→ PE_B: data + sender_seq=3
PE_B →W→ PE_A: data + sender_seq=5 + credit_ack=4 ← credit이 data에 합쳐짐
```
| 장점 | 단점 |
|------|------|
| Credit 전용 packet 제거 → NoC BW 절약 | Unidirectional 패턴에서는 fallback 필요 |
| Bidirectional allreduce에서 credit latency → 0 | Flit header에 8B 추가 (overhead 미미) |
| | Logic 복잡도 소폭 증가 |
**평가**: 현재 설계의 우수한 최적화.
Bidirectional allreduce에서 credit packet을 완전 제거 가능.
Standalone credit fallback도 유지. **v2로 채택 권고.**
---
## 9. Recommendations
1. **현재 IPCQ-DMA co-design을 기본 하드웨어 설계로 채택**
— 단순하고, 면적 효율적이며, 2nm에서 timing/power 문제 없음
2. **n_slots를 반드시 power-of-2로 제약**
— mod 연산을 AND mask로 대체, critical path 단축
3. **TCM banking에서 IPCQ region 전용 bank 할당**
— compute와의 bank conflict 방지
4. **v2에서 Credit-in-Data Piggyback (Section 8.4) 추가 검토**
— bidirectional 패턴에서 credit overhead 제거
---
## 10. Open Questions
- [ ] IPCQ slot region size를 TCM의 몇 %까지 허용할 것인가? (현재 가정: ~1MB / 16MB = 6.25%)
- [ ] Credit VC를 별도로 둘 것인가, vc_comm에 multiplexing할 것인가?
- [ ] Inter-SIP link에서의 flit format 호환성 검증 필요
- [ ] n_slots 최대값 제한? (8 directions × 8 slots × 64KB = 4MB → TCM의 25%)