Charge per-tier bandwidth + setup overhead at IPCQ slot WRITE
(receiver inbound DMA, in pe_dma._handle_ipcq_inbound) and slot
READ (recv consume, in pe_ipcq._handle_recv). Tier table
(common/ipcq_types.py):
tcm : 512 GB/s, 0 ns
sram : 128 GB/s, 2 ns
hbm : 32 GB/s, 6 ns
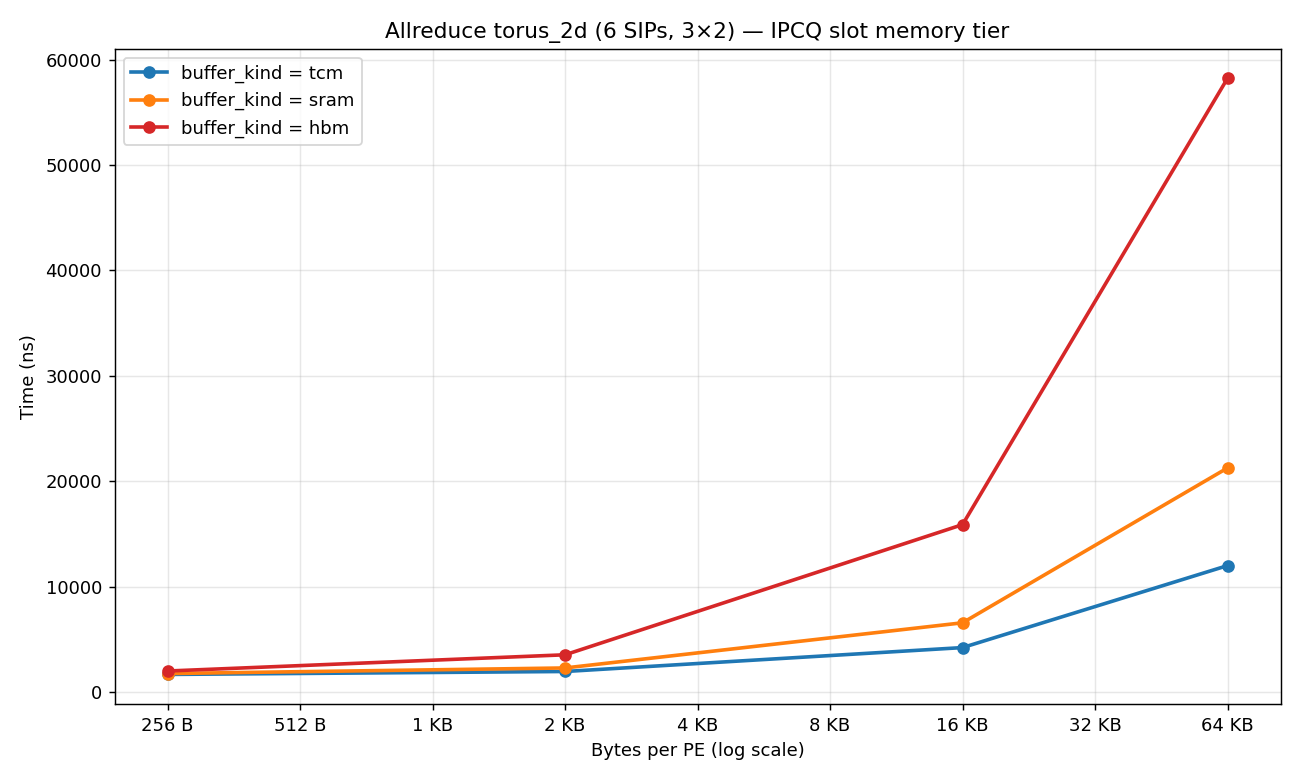
Before this change, slot read/write was free regardless of
buffer_kind, making memory-tier choice invisible in simulated
latency. After the change, swapping buffer_kind in ccl.yaml
produces measurable per-tier separation in allreduce latency.
Tests:
test_ipcq_buffer_kind_latency.py — three micro-tests asserting
tcm < sram < hbm ordering, payload-scaling, and that
buffer_kind sensitivity grows with payload (credit-only path
stays fabric-bound).
test_allreduce_buffer_kind_sweep.py — 12-config parametrized
sweep emitting buffer_kind_sweep.png (3 lines, torus_2d).
conftest sessionfinish hook generalised to dispatch multiple
sweep aggregators (allreduce + buffer-kind).
Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com>
68 KiB
1300x780px
68 KiB
1300x780px
{kind=link}
{kind=link}