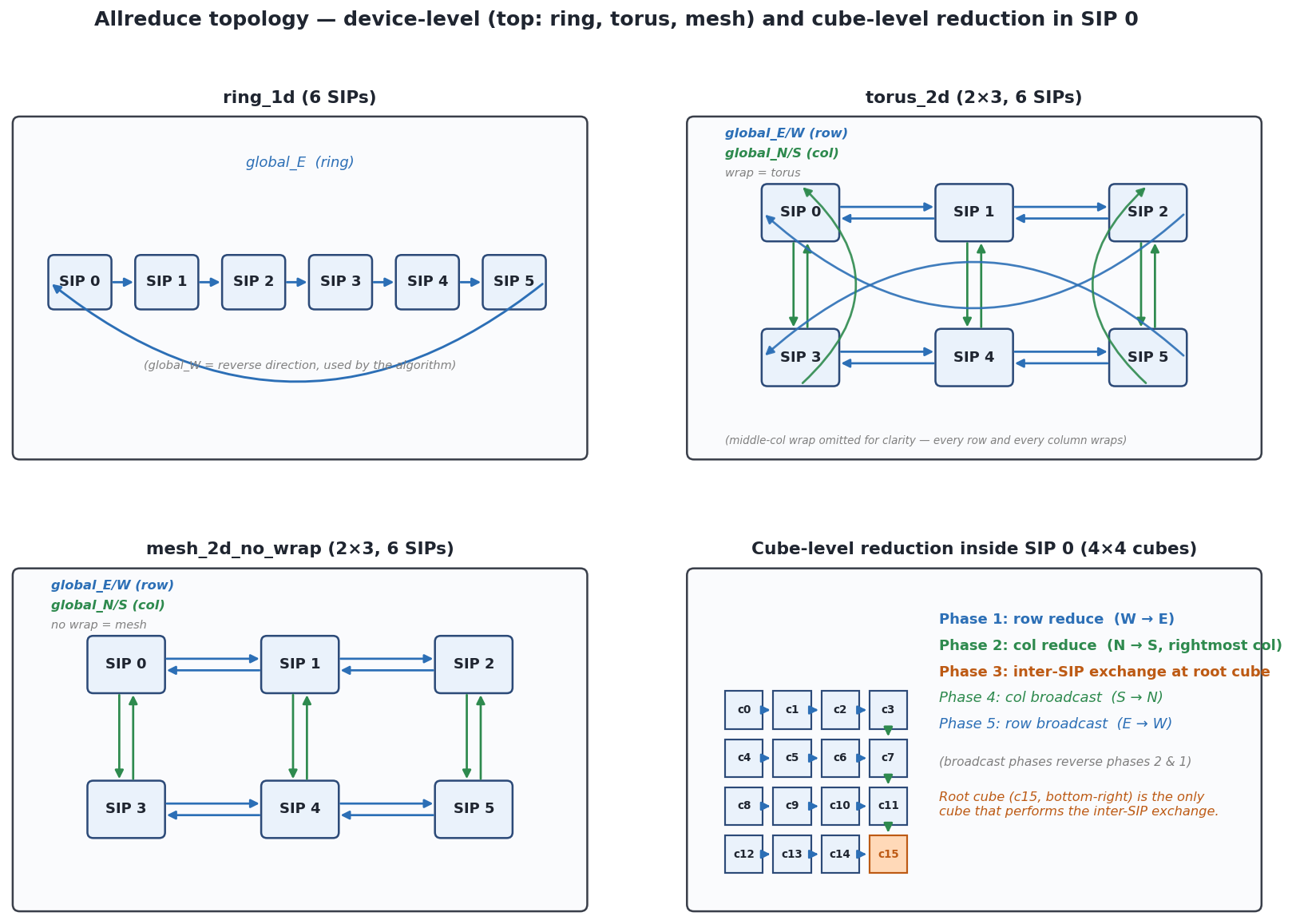
- intercube_allreduce: add single-cube fast path that skips intra-SIP mesh reduce and goes directly to inter-SIP exchange. Fixes IPCQ deadlock when TP launches kernel on one cube per SIP. - distributed.py: derive effective cube dims from tensor shard placement instead of hardcoding topology mesh size. - pyproject.toml: add matplotlib>=3.7 to dependencies. - pe_dma.py (prior commit): add MMU translation in pipeline DMA path. 577 passed, 0 failed (was 529 passed, 10 failed). Co-Authored-By: Claude Opus 4.6 (1M context) <noreply@anthropic.com>
194 KiB
1618x1157px
194 KiB
1618x1157px
{kind=link}
{kind=link}